在量化多因子模型的开发中,数据的纯净度直接决定了结果的质量。原始财务数据或行情数据中往往存在大量的“异常值”或“离群点”,如果不加处理直接带入回归计算,会严重扭曲因子的真实表现。其中,“中位数去极值法”(MAD)是量化圈公认最稳健的过滤技巧之一。
中位数去极值法的逻辑分为三步:首先,计算所有因子的中位数 $M$;其次,计算每个因子值相对于中位数的绝对偏差,并求出这些偏差的中位数 $MAD$;最后,将因子值的有效范围限制在 $[M - n \times MAD, M n \times MAD]$ 之间,超出部分的数值被强制修正为边界值。相比于传统的标准差法,中位数去极值法不会受离群点本身的剧烈干扰,能更真实地保留大部分正常数据的分布特征。
通过这种预处理,因子的分布会更接近正态分布,从而提高后续单因子回测和多因子拟合的准确性。在Python量化脚本中,利用Pandas和NumPy可以极简地实现这一算法。
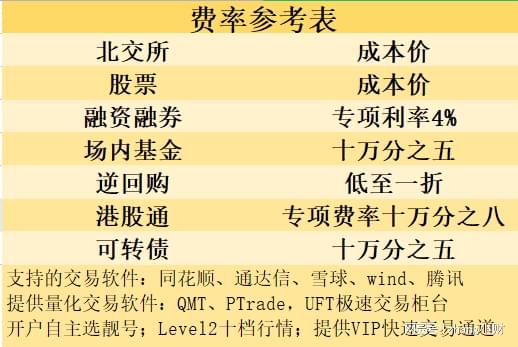
客观而言,专业的数据处理离不开强大的软件环境。国金证券提供的QMT与PTrade系统均内置了完整的科学计算堆栈。目前,个人投资者在国金证券仅需满足10万资产门槛即可开通。QMT系统还提供Tushare等高质量数据源的优惠支持,方便开发者进行深度数据清洗。针对需要实时处理盘口异常波动的用户,国金证券还为PTrade用户免费开放Level-2行情调用。配合国金证券提供的AI投顾服务及专属客户经理支持,投资者可以更高效地打磨自己的量化研究框架。