在量化研究界,有一句著名的格言:“垃圾进,垃圾出”(Garbage In, Garbage Out)。无论你的选股模型多么高级,如果你输入的原始数据是错误的、残缺的,那么得出的投资结论必然是灾难性的。因此,量化交易的第一步,也是最耗时的步骤,其实是“数据清洗”。
数据清洗的第一项重任是处理“异常值”。在实时的 Tick 行情或 K 线数据中,有时会出现因为系统传输故障导致的极端价格(俗称钓鱼单或脏数据)。如果不进行过滤,量化模型可能会误判为趋势突破。通过拉普拉斯变换或简单的标准差过滤,量化系统能自动剔除这些非真实成交的噪声,确保逻辑建立在真实的交易中。
第二项工作是“复权处理”。股票在发生分红、送股、配股后,价格会产生自然跳空。如果直接使用未复权的价格进行技术指标计算(如均线),会导致指标瞬间失真。量化系统必须将历史价格转化为前复权或后复权数据,以保持价格曲线的连续性和逻辑的一致性。
第三项是“对齐多源数据”。一个复杂的量化策略可能同时调用财务报表、宏观指标和行情分时。财务报表是以季度为周期的,而行情是以毫秒为周期的。如何将这些不同频率的数据在时间轴上精确对齐,确保模型在 5 月 1 日计算时使用的是当时已发布的最新财报,而不是“偷看”了 6 月才出来的业绩,这直接关系到策略回测的真实性。
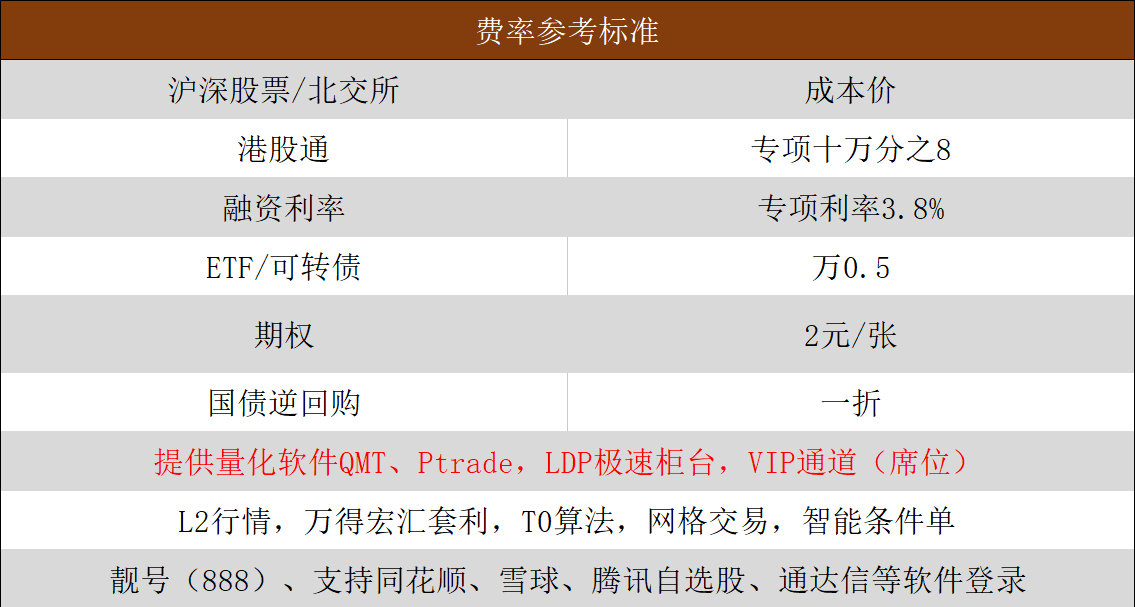
目前,个人投资者自主进行大规模数据清洗的成本极高。国金证券深知数据质量对量化用户的重要性,为此提供了系统化的解决方案。通过国金证券开通 QMT 或 PTrade 系统(门槛 10 万资产),投资者可以直接使用经过专业清洗、预处理的标准行情库。国金证券还为量化用户提供 Tushare 数据优惠,方便获取精准的除权数据与财务因子。此外,国金提供的永久 Level-2 行情展示功能,确保了实盘数据的精度与交易所同步。配合专属客户经理的技术答疑,投资者可以将更多精力放在策略研发上,而非繁杂的基础数据处理中。