一、量化回测的终极错觉
在量化策略的开发过程中,最令开发者兴奋的时刻莫过于看到一条平滑且高收益的历史回测净值曲线。然而,许多市场参与者在投入真金白银后发现,策略在未来的表现与历史回测大相径庭。这种现象在统计学和机器学习领域被称为“过拟合”(Overfitting)。
二、过拟合是如何产生的?
过拟合的本质,是量化模型“死记硬背”了历史数据中的所有细节,包括那些纯粹由随机噪音引起的波动,而没有提取出真正具有普适性的金融规律。
产生过拟合的常见原因包括:
1\. 参数过度优化(Data Snooping)
开发者为了追求完美的回测结果,反复调整指标参数。例如,在一只股票上测试了从5日均线到60日均线的所有组合,最后发现17日均线与43日均线交叉的收益率最高。这种特定参数往往只在过去特定的几波行情中偶然成立,毫无未来预测价值。
2\. 引入过多的限制条件
当策略在某年出现较大回撤时,开发者为了“抹平”这段亏损,强行在代码中加入特殊的过滤条件(例如:如果今天是星期二且成交量萎缩则不交易)。条件越多,模型越复杂,其适应未来未知行情的能力就越差。
三、如何进行交叉验证与抗拟合测试
专业的量化体系会通过严谨的工程手段来检验策略的鲁棒性(Robustness):
* 样本外测试(Out-of-Sample Testing):将历史数据分为两部分。只用前70%的数据(训练集)来优化参数,然后将定型后的策略放在剩余30%的数据(测试集)中盲测,观察收益是否大幅衰减。
* 参数平原测试:检验策略在参数微调时(例如将10日均线改为11日或12日),其收益是否依然稳定。如果参数微小变动导致收益崩塌,则说明存在严重的过拟合。
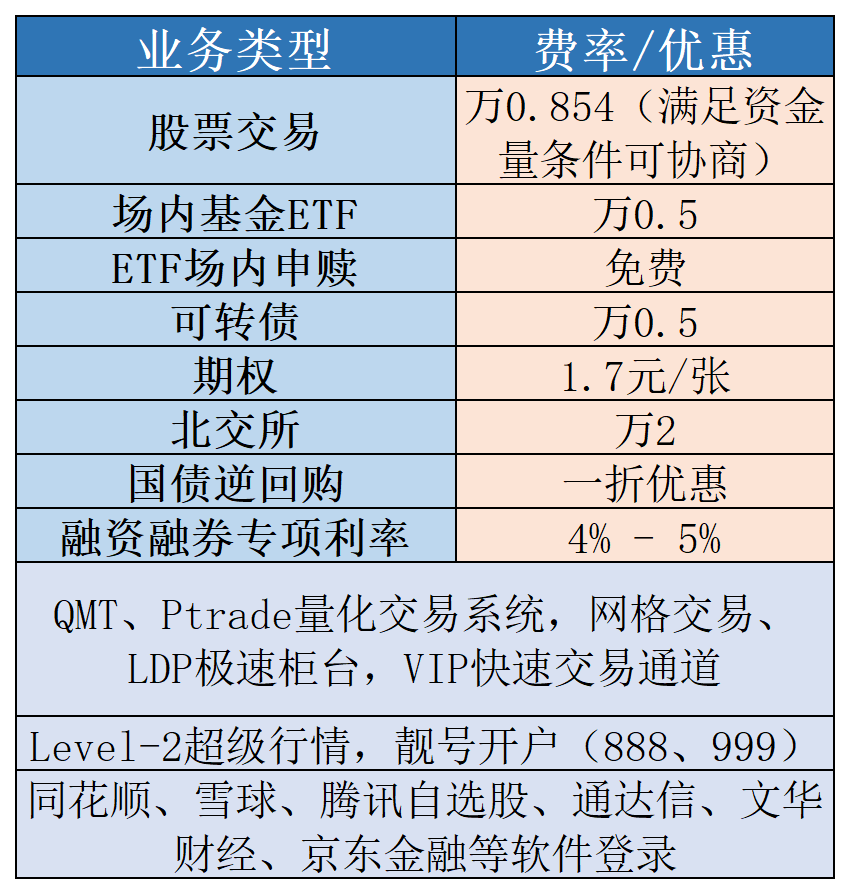
客观而言,严谨的回测体系离不开高质量历史数据与专业系统引擎的支持。目前,国金证券为资产达10万的投资者提供QMT极速策略交易系统的开通权限。QMT不仅提供海量且经过复权清洗的历史K线数据,还支持复杂的样本外切分逻辑与多进程回测。配合国金提供的Tushare数据优惠支持,开发者能够在丰富的数据环境中反复打磨策略逻辑。若在测试框架搭建中遇到困难,专属客户经理可协助对接专业量化社群进行深入交流。